Showing
- object-storage/s3-clients.md 44 additions, 0 deletionsobject-storage/s3-clients.md
- object-storage/s3-features.md 419 additions, 0 deletionsobject-storage/s3-features.md
- object-storage/s3-service-screenshots/direct_upload.png 0 additions, 0 deletionsobject-storage/s3-service-screenshots/direct_upload.png
- object-storage/s3-service-screenshots/s3_backup.png 0 additions, 0 deletionsobject-storage/s3-service-screenshots/s3_backup.png
- object-storage/s3-service-screenshots/s3_distribution.png 0 additions, 0 deletionsobject-storage/s3-service-screenshots/s3_distribution.png
- object-storage/s3-service.cs.md 10 additions, 0 deletionsobject-storage/s3-service.cs.md
- object-storage/s3-service.md 57 additions, 0 deletionsobject-storage/s3-service.md
- object-storage/s3browser-screenshots/s3b-multipart1.png 0 additions, 0 deletionsobject-storage/s3browser-screenshots/s3b-multipart1.png
- object-storage/s3browser-screenshots/s3b-multipart2.png 0 additions, 0 deletionsobject-storage/s3browser-screenshots/s3b-multipart2.png
- object-storage/s3browser-screenshots/s3browser1.png 0 additions, 0 deletionsobject-storage/s3browser-screenshots/s3browser1.png
- object-storage/s3browser-screenshots/s3browser2.png 0 additions, 0 deletionsobject-storage/s3browser-screenshots/s3browser2.png
- object-storage/s3browser-screenshots/s3browser3.png 0 additions, 0 deletionsobject-storage/s3browser-screenshots/s3browser3.png
- object-storage/s3browser-screenshots/s3browser4.png 0 additions, 0 deletionsobject-storage/s3browser-screenshots/s3browser4.png
- object-storage/s3browser.md 45 additions, 0 deletionsobject-storage/s3browser.md
- object-storage/s3cmd.md 115 additions, 0 deletionsobject-storage/s3cmd.md
- object-storage/s5cmd.md 36 additions, 0 deletionsobject-storage/s5cmd.md
- object-storage/template.md 20 additions, 0 deletionsobject-storage/template.md
- object-storage/veeam-backup.md 12 additions, 0 deletionsobject-storage/veeam-backup.md
- object-storage/winscp-screenshots/winscp_setup1en.png 0 additions, 0 deletionsobject-storage/winscp-screenshots/winscp_setup1en.png
- object-storage/winscp-screenshots/winscp_setup2en.png 0 additions, 0 deletionsobject-storage/winscp-screenshots/winscp_setup2en.png
object-storage/s3-clients.md
0 → 100644
object-storage/s3-features.md
0 → 100644
{kind=link}

70.5 KiB
{kind=link}

71.3 KiB
{kind=link}

206 KiB
object-storage/s3-service.cs.md
0 → 100644
object-storage/s3-service.md
0 → 100644
{kind=link}
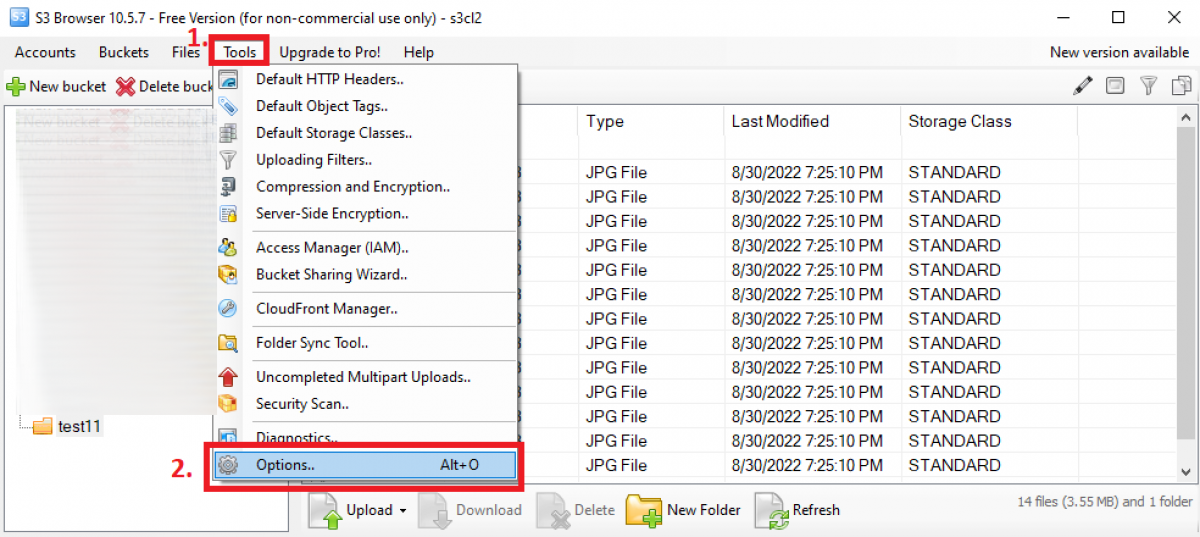
394 KiB
{kind=link}
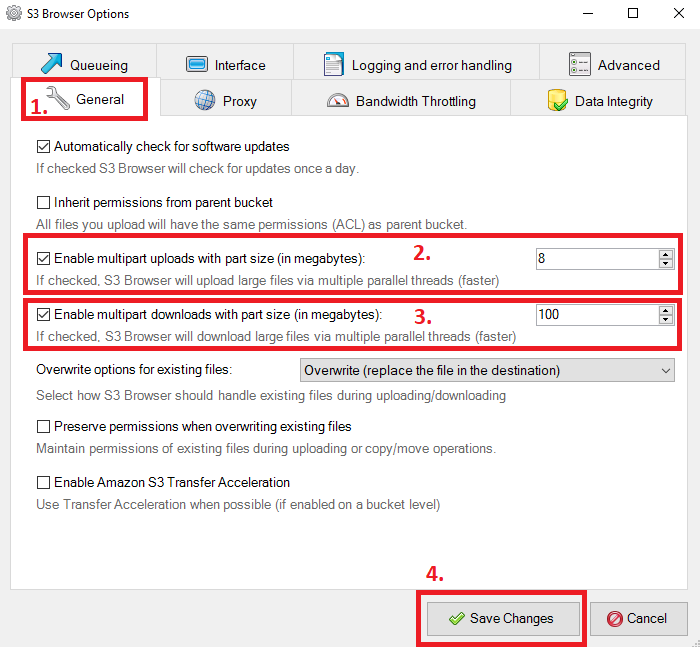
37.3 KiB
{kind=link}
223 KiB
{kind=link}
230 KiB
{kind=link}
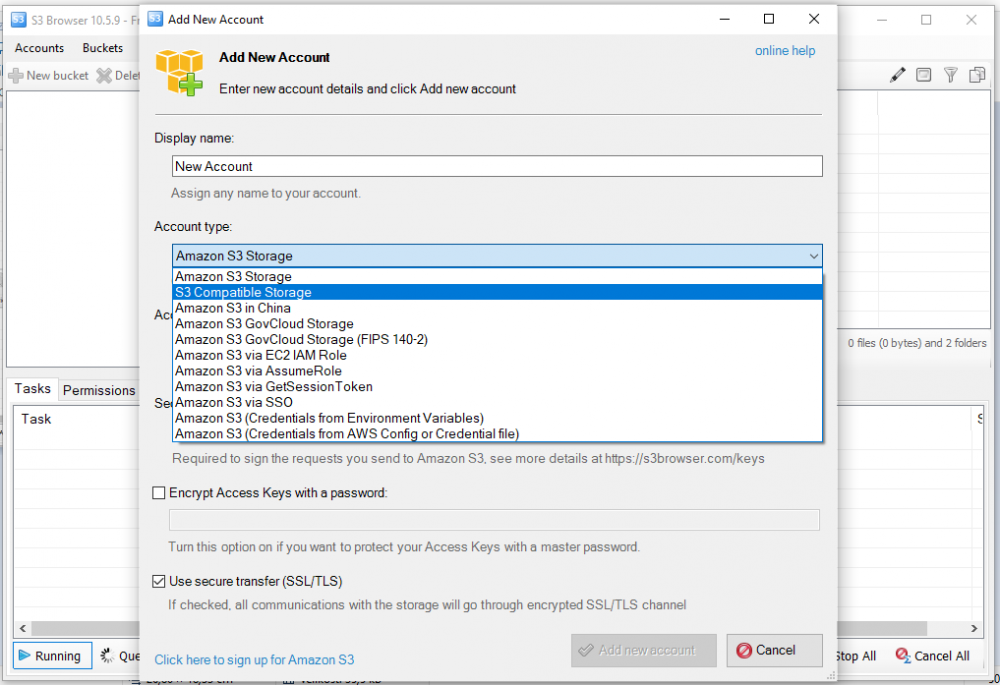
345 KiB
{kind=link}
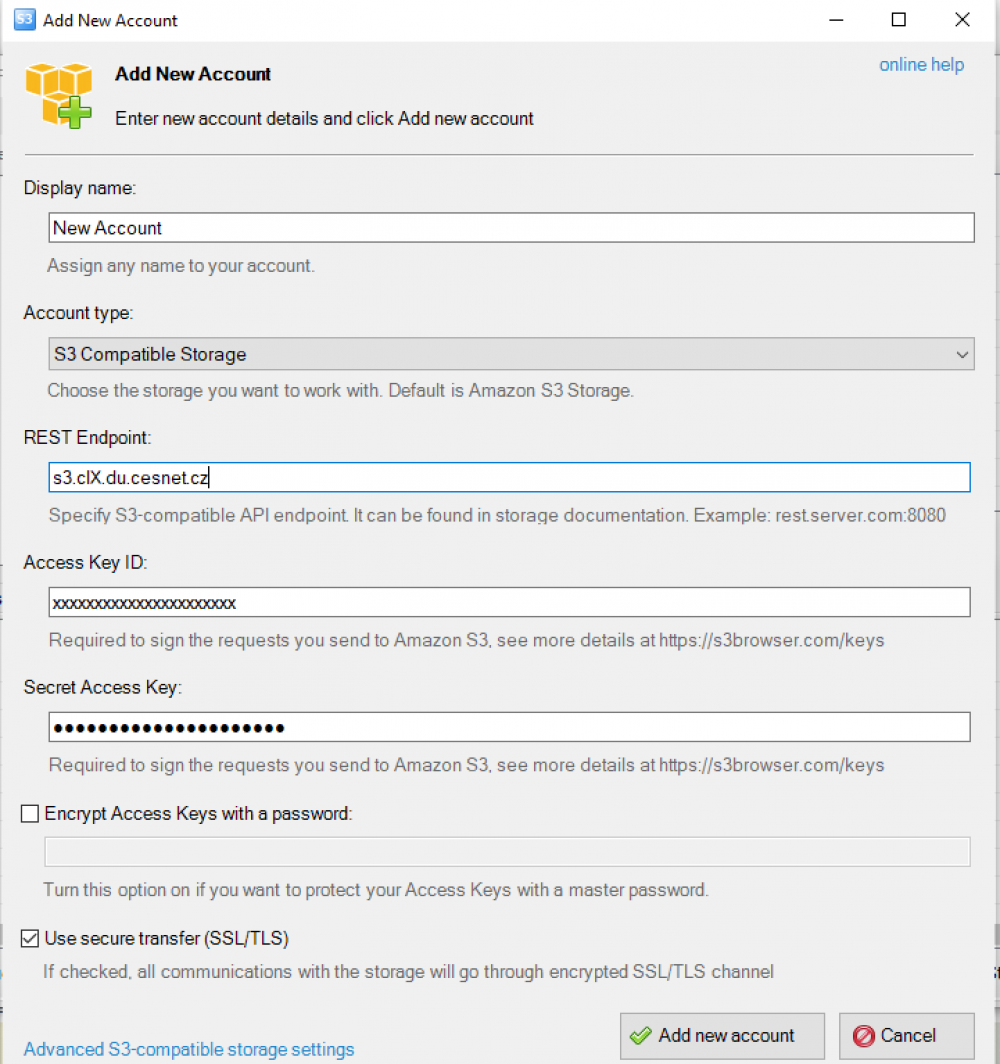
511 KiB
object-storage/s3browser.md
0 → 100644
object-storage/s3cmd.md
0 → 100644
object-storage/s5cmd.md
0 → 100644
object-storage/template.md
0 → 100644
object-storage/veeam-backup.md
0 → 100644
{kind=link}

218 KiB
{kind=link}

288 KiB